728x90
실무에서 query문을 짜면서 구글링을 하다가 흥미로운 질문을 발견해 퇴근 후 집에와서 찾아봤습니다.

위 이미지를 보게되면 JOIN과 IN절은 만일 컬럼이 유니크하지 않다면 다른 결과값을 나온다고 설명합니다.
그래서 IN절과 WHERE이 같은 결과값을 같기 위해서는 JOIN에 DISTINCT를 사용해서 중복 제거 후 사용해야한다는 겁니다.
그래서 직접 궁금해서 query문을 적어 진행해보았습니다.
CREATE TABLE IF NOT EXISTS a (
col INT,
data VARCHAR(50)
);
CREATE TABLE IF NOT EXISTS b (
col INT
);
INSERT INTO a (col, data) VALUES
(1, 'A'),
(2, 'B'),
(3, 'C');
INSERT INTO b (col) VALUES
(1),
(2),
(2);
먼저 예시 테이블 2개를 만들어 준 후
JOIN
-- DISTINCT가 사용되지 않은 JOIN
-- 중복된 값까지 출력
SELECT a.*
FROM a
JOIN b
ON a.col = b.col;
먼저 JOIN을 하게 되면

이러한 결과 값이 나오게 됩니다.
JOIN 쿼리는 중복된 b.col에 대한 a의 모든 행을 반환합니다.
WHERE IN
-- WHERE IN 사용
SELECT a.*
FROM a
WHERE col IN
(
SELECT col
FROM b
);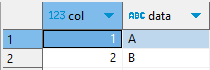
IN 쿼리는 중복을 고려하지 않고 단순히 해당 값이 b 테이블에 존재하는지만 확인합니다.
그래서 b.col에 중복 값이 있더라도 a에서 해당 값에 대한 행은 한 번만 반환됩니다.
결론
위의 예시에서 볼 수 있듯이, JOIN 쿼리 결과에서 a 테이블의 col 값 2가 두 번 나타나는 반면, IN 쿼리 결과에서는 col 값 2가 한 번만 나타납니다. 이는 b 테이블의 col 컬럼 값 중복이 JOIN 쿼리의 결과에는 영향을 미치지만 IN 쿼리의 결과에는 영향을 미치지 않기 때문입니다.
728x90
반응형
'SQL' 카테고리의 다른 글
| DB 쿼리가 느릴 때 확인해야 할 것 (0) | 2025.03.24 |
|---|---|
| SQL에서 WHERE 1=1을 사용하는 이유는? (0) | 2025.03.14 |
| [SQL] Date Format 함수 (formatting parameter) (1) | 2024.03.28 |
| [MYSQL] 함수 만들기 (FUNCTION) (0) | 2024.03.20 |
| [MYSQL] 자주 사용하는 날짜형 함수 정리 (0) | 2024.03.19 |