
데이터 파이프라인에서 오류는 전체 시스템에 큰 문제를 일으킬 수 있습니다.
누락된 컬럼, NULL 값, 비정상 범위의 숫자 값 등 단순해 보이지만 이런 데이터 오류는 리포트 실패, 마케팅 대상 오류, 모델 성능 하락 등으로 이어질 수 있습니다.
Airflow로 검증도 자동화할 수 있습니다.
목표
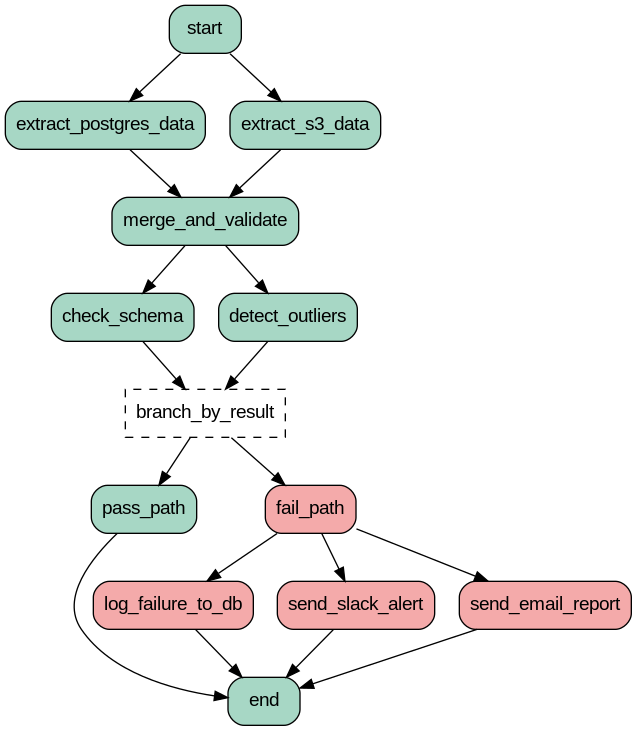
- PostgreSQL과 S3에서 데이터를 추출합니다.
- 데이터를 통합한 뒤 스키마와 이상값을 검사합니다.
- 실패 시 Slack 알림, 이메일 전송, DB 로그를 자동화 작업을 진행합니다.
사용기술
- Apache Airflow 2
- Python Pandas
- PostgresHook
- BranchPythonOperator
- Airflow 이메일 기능
DAG 구성 흐름도
Airflow 코드
from airflow.decorators import dag, task
from airflow.operators.python import BranchPythonOperator
from airflow.operators.dummy import DummyOperator
from airflow.utils.dates import days_ago
from airflow.hooks.postgres_hook import PostgresHook
from airflow.utils.email import send_email
import pandas as pd
import os
import requests
@task
def extract_postgres_data():
try:
pg_hook = PostgresHook(postgres_conn_id='test_postgres')
df = pg_hook.get_pandas_df("SELECT user_id, age, signup_date FROM users WHERE created_at >= NOW() - INTERVAL '1 DAY'")
return df.to_json(date_format='iso')
except Exception as e:
raise ValueError(f"PostgreSQL 데이터 추출 실패: {e}")
@task
def extract_s3_data():
try:
df = pd.DataFrame({
'user_id': [1001, 1002],
'age': [32, 29],
'signup_date': pd.to_datetime([
'2025-03-01',
'2025-03-02'])
})
return df.to_json(date_format='iso')
except Exception as e:
raise ValueError(f"S3 데이터 생성 실패: {e}")
@task
def merge_and_validate(pg_json, s3_json):
try:
df_pg = pd.read_json(pg_json, convert_dates=True)
df_s3 = pd.read_json(s3_json, convert_dates=True)
df_combined = pd.concat([df_pg, df_s3]).drop_duplicates('user_id')
return df_combined.to_json(date_format='iso')
except Exception as e:
raise ValueError(f"데이터 병합 실패: {e}")
@task
def check_schema(data_json):
try:
df = pd.read_json(data_json, convert_dates=True)
expected_columns = {
'user_id': 'int64',
'age': 'float64',
'signup_date': 'datetime64[ns]'
}
for col, dtype in expected_columns.items():
if col not in df.columns or str(df[col].dtype) != dtype:
return "fail"
return "pass"
except Exception as e:
print(f"스키마 검증 오류: {e}")
return "fail"
@task
def detect_outliers(data_json):
try:
df = pd.read_json(data_json, convert_dates=True)
if df['age'].mean() > 100 or df['age'].min() < 0:
return "fail"
return "pass"
except Exception as e:
print(f"이상값 탐지 오류: {e}")
return "fail"
def branch_decider(**context):
try:
schema_result = context['ti'].xcom_pull(task_ids='check_schema')
outlier_result = context['ti'].xcom_pull(task_ids='detect_outliers')
return "fail_path" if "fail" in [schema_result, outlier_result] else "pass_path"
except Exception as e:
print(f"분기 처리 실패: {e}")
return "fail_path"
@task
def log_failure_to_db():
try:
pg_hook = PostgresHook(postgres_conn_id='test_postgres')
pg_hook.run("INSERT INTO data_test_failures (timestamp, reason) VALUES (NOW(), 'Validation Failed')")
except Exception as e:
print(f"DB 기록 실패: {e}")
@task
def send_slack_alert():
try:
webhook = os.getenv("SLACK_WEBHOOK_URL")
if webhook:
response = requests.post(webhook, json={"text": "데이터 테스트 실패 - 스키마 또는 이상값 오류 발생"})
response.raise_for_status()
except Exception as e:
print(f"Slack 전송 실패: {e}")
@task
def send_email_report():
try:
html = "<h3>Airflow 테스트 보고서</h3><p>전체 테스트 결과: 실패</p>"
send_email(to=["data-team@example.com"], subject="Airflow 데이터 테스트 실패", html_content=html)
except Exception as e:
print(f"이메일 전송 실패: {e}")
@dag(schedule_interval='@daily', start_date=days_ago(1), catchup=False, tags=['data_test'])
def advanced_data_test_dag():
start = DummyOperator(task_id='start')
end = DummyOperator(task_id='end')
branch = BranchPythonOperator(
task_id='branch_by_result',
python_callable=branch_decider,
provide_context=True
)
pass_path = DummyOperator(task_id='pass_path')
fail_path = DummyOperator(task_id='fail_path')
pg_data = extract_postgres_data()
s3_data = extract_s3_data()
merged = merge_and_validate(pg_data, s3_data)
schema_result = check_schema(merged)
outlier_result = detect_outliers(merged)
fail_task1 = log_failure_to_db()
fail_task2 = send_slack_alert()
fail_task3 = send_email_report()
start >> [pg_data, s3_data]
[pg_data, s3_data] >> merged >> [schema_result, outlier_result] >> branch
branch >> pass_path >> end
branch >> fail_path >> [fail_task1, fail_task2, fail_task3] >> end
advanced_data_test_dag = advanced_data_test_dag()
함수 정의
1. extract_postgres_data()
- PostgreSQL로부터 최근 하루 동안 적재된 사용자 데이터를 추출 함수
2. extract_s3_data()
- S3 또는 외부 API로 부터 데이터를 받아오는 작업을 테스트할 수 있는 mock데이터 생성 함수
3. merge_and_validate()
- 두 데이터 소스를 병합하고, 유일 사용자 기준 중복를 제거하여 하나의 통합된 dataset을 생성
4. check_schema()
- 데이터의 컬럼 명세와 데이터 타입이 예상과 일치하는지를 검증
5. detect_outliers()
- 데이터 내 이상값(outlier)을 단순 통계 기준으로 탐지
6. branch_decider()
- 검증 결과에 따라 이후 작업을 pass_path 또는 fail_path로 분기 처리
- XCom 값을 사용해 의존 Task 결과를 직접 비교
7. log_failure_to_db()
- 테스트 실패 기록을 PostgreSQL DB에 저장, 장기적인 이슈 분석이 가능하게 설계
- DB연결 실패시에도 로그만 출력하고 DAG 실패는 방지
8. send_slack_alert()
- 테스트 실패 시 실시간으로 알림
- webhook 설정 누락 시 예외 처리
- 요청 실패 (response.raise_for_status) 확인
9. send_email_report()
- 테스트 실패 결과를 HTML 포맷으로 구성된 이메일로 전송
- send_email() 실패 시에도 DAG 중단 방지
해당 프로젝트를 진행하게 된 계기가 실무에서 데이터 QA를 진행할 때마다 확인하던 걸
Airflow를 활용해서 자동화를 만들게 되었습니다.
'Data Engineer' 카테고리의 다른 글
| PySpark vs. Scala Spark 어떤 언어를 선택해야할까? (0) | 2025.04.02 |
|---|---|
| Airflow XCom 태스크 간 데이터 전달 (0) | 2025.03.28 |
| Apache Spark vs Apace Flink (0) | 2025.03.26 |
| Redshift vs BigQuery vs Snowflake (0) | 2025.03.25 |
| Spark SQL에서 자주 발생하는 오류 2 (0) | 2025.03.20 |