
결측치란?
데이터 분석에서는 데이터가 완전한 경우가 거의 없습니다.
예를 들어 "누군가 설문을 제출했지만 나이를 안 적었다", "센서가 잠깐 오작동해서 온도가 기록되지 않았다."
등 수많은 이유로 인해 결측치는 자연스럽게 발생합니다.
이 결측치를 제대로 처리하지 않으면 모델 성능이 급격히 떨어지고, 분석 결과가 왜곡되는 치명적인 문제가 생깁니다.
결측치가 발생하는 대표적인 이유는 다음과 같습니다.
(이 외에도 다양한 이유가 있습니다.)
| 원인 | 예시 |
| 입력 누락 | 사용자가 설문 항목을 건너뜀 |
| 수집 오류 | 센서 고장, API 응답 없음 |
| 시스템 마이그레이션 문제 | 새로운 시스템에 값이 안 옮겨짐 |
| 의도적 생략 | 민감 정보 (수입 등) 미기재 |
만일 위와같은 원인으로 결측치가 발생했는데 무시하고 분석할 경우 다음과 같은 오류 및 실패가 발생할 수 있습니다.
- 통계량 계산 오류
- 평균, 분산, 상관관계 등에서 NaN이 섞이면 정확한 결과가 나오지 않음
- 시각화 오류
- 결측치가 있는 데이터를 시각화하면 이상한 그래프가 그려지거나 에러 발생.
- 모델 학습 실패
- 대부분의 머신러닝 라이브러리(scikit-learn 등)는 결측치를 포함한 상태로 학습 불가.
이제 부터 결측치 탐지 및 처리 방법에 대해 알아보도록 하겠습니다.
결측치 탐지 및 처리 방법
이번에 사용할 데이터 셋은 kaggle의 Titanic-Dataset.csv 입니다.
import pandas as pd
df = pd.read_csv('titanic.csv')
df.isnull().sum()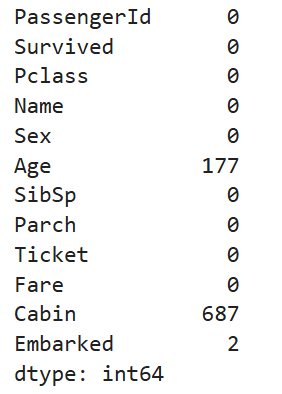
- .isnull( ) 또는 .isna( ) 는 True/False 반환
- .sum( ) 으로 각 열에 몇 개의 결측치가 있는지 파악
또는 .info( ) 로 전체 데이터 타입과 결측 유무를 확인할 수 있습니다.
df.info()
결측치 처리 방법
1. 삭제 (Drop)
- 단순하고 안전한 방법이지만 정보 손실이 클 수 있습니다.
(그리고 Drop을 하기전에 df를 복사해서 원본 데이터를 저정하는 방법을 추천드립니다.)
df_copy = df.copy() # 원본 데이터 셋 복사
df_copy.dropna(inplace=True) # 행 삭제
df_copy.isnull().sum() # 결측치가 삭제되었는지 확인# 특정 열만 삭제
df.drop(columns=['Cabin'], inplace=True)
상황에 따라 다르겠지만 삭제하는 방법보다는 대체(Imputation)을 사용하는 방법이 더 좋습니다.
2. 평균/중앙값 대체 (수치형에 자주 사용)
# Age: 평균값으로 대체
df['Age'].fillna(df['Age'].mean(), inplace=True)
3. 최빈값 대체 (범주형에 자주 사용)
# Embarked: 최빈값으로 대체
df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True)
4. KNNImputer (다른 특성 기반 예측 값으로 채움)
KNNImputer의 대해서 간단하게 설명하자면 scikit-learn에서 제공하는 클래스입니다.
비슷한 값을 가진 샘플끼리 비교하여 결측치를 보완합니다.
예를 들어 Age가 결측인 승객의 나이 외 다른 특징(성별, 객실 등)이 유사한 사람들의 Age 평균으로 채워집니다.
from sklearn.impute import KNNImputer
import pandas as pd
# 분석에 사용할 수치형 열 선택 (예: Age, Fare 등)
num_cols = ['Age', 'Fare']
# KNNImputer는 수치형 데이터만 처리 가능하므로 해당 열만 추출
imputer = KNNImputer(n_neighbors=5)
df[num_cols] = imputer.fit_transform(df[num_cols])
# 확인
print(df[num_cols].isnull().sum())

- n_neighbors=5: 결측치를 채울 때 기준이 될 주변 5개 이웃의 평균값을 사용
- weights='uniform' (기본): 이웃 가중치 동일, 'distance'를 설정하면 가까운 이웃일수록 가중치를 높임
주의 사항
- 모든 입력값은 스케일이 비슷해야 합니다. Fare처럼 값의 범위가 큰 경우 StandarScaler로 사전 정규화가 필요할 수 있습니다.
- 범주형 변수는 Label Encoding 후에 사용할 수 있지만, KNNImputer는 수치형에만 직접 적용해야 합니다.
| 전략 | 장점 | 단점 | 사용 조건 |
| 삭제 | 간단하고 빠름 | 정보 손실, 샘플 수 감소 | 결측치가 적거나 무작위로 분포할 때 |
| 평균/최빈값 대체 | 통계적으로 합리적이고 구현 쉬움 | 데이터의 분산을 축소하거나 왜곡 가능 | 데이터가 정규분포에 가까울 때 |
| 예측 기반 대체 | 가장 정확한 추정 가능 | 구현 복잡, 계산량 많음 | 고품질 데이터가 있고 성능이 중요할 때 |
결측치 관련 실수들
- 범주형 데이터에 평균값 대체: 범주형은 최빈값을 사용해야 함
- 학습용/테스트용 데이터에 다른 방식 적용: 일관된 처리 필요
- 대체 후 타입이 바뀌는 현상: .astype(int)으로 수치형 복원
- 숫자 0을 결측치로 오해: 0은 결측치가 아님
결측치가 많은 열은 Drop을 우선 고려하되, 해당 열이 의미 있는 정보를 담고 있다면 예측 기반 대체를 활용해야합니다.
.fillna( )는 inplace=True 옵션으로 원본 변경이 가능합니다.
sklearn의 SimpleImputer나 KNNImputer를 통해 파이프라인화도 가능합니다.
정리
결측치는 데이터 분석의 정확성을 해치는 대표적 원인 중 하나입니다.
반드시 탐지 후 원인 분석, 처리 전략 결정의 순서를 따라야 합니다.
처리 방식에 따라 분석 결과나 모델 성능이 크게 달라집니다.
참고 자료
- Kaggle Titanic Dataset
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
- Scikit-learn 공식 문서: Imputation strategies
'Data Analysis' 카테고리의 다른 글
| 정규화(Normalization) vs 표준화(Standardization) (0) | 2025.05.14 |
|---|---|
| 이상치(Outliers) 탐지와 처리 방법 (0) | 2025.05.14 |
| Hypothesis Test란? (0) | 2023.08.23 |
| 데이터 분석가의 역할 (Data Analyst) (0) | 2023.08.11 |
| EDA의 개념과 데이터 분석 (0) | 2023.04.30 |