
728x90
Series - 1차원 데이터 구조
Pandas의 1차원 데이터 구조로, 아래와 같이 값 + 인덱스로 구성되어 있습니다.
import pandas as pd
s = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
print(s)출력결
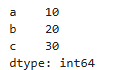
- values: [10, 20, 30]
- index: ['a', 'b', 'c']
- dtype: int64
Serise는 단순한 리스트가 아니라 인덱스를 명확히 가진 1차이눠 벡터형 데이터
사용자 점수, 제품 가격 목록 등 단일 열 데이터를 다룰 때 주로 사용된다.
user_scores = pd.Series([87, 92, 75], index=['user_1', 'user_2', 'user_3'])
DataFrame - 2차원 테이블 구조
DataFrame은 엑셀처럼 행(row)과 열(column)로 이루어진 2차원 구조다.
데이터베이스 테이블처럼 생각하면 이해하기 쉽다.
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'score': [88, 92, 85]
})
df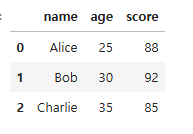
- .columns: ['name', 'age', 'score']
- .index: [0, 1, 2]
- .shape: (3, 3)
로그데이터, 고객 정보, 제품 카탈로그 등 여러 개의 속성을 가진 데이터를 처리할 때 필수
| 항목 | Series | DataFrame |
| 차원 | 1차원 | 2차원 |
| 형태 | 단일 열 | 행 + 열 테이블 |
| 인덱스 | row index | row index + column |
| 사용 상황 | 점수, 가격, 단일 값 목록 등 | 전체 테이블 구조, 분석/전처리 등 |
Series는 보조적인 느낌이고, DataFrame이 메인이다.
Pandas 연산 대부분은 DataFrame를 기반으로 설계되어있다.
리스트로 받은 데이터를 DataFrame로 구조화하기
data = [
['Alice', 25, 88],
['Bob', 30, 92],
['Charlie', 35, 85]
]
df = pd.DataFrame(data, columns=['name', 'age', 'score'])
이렇게만 해도 비정형 리스트 → 구조화된 테이블로 변환 가능.
Pandas는 이런 '구조화'의 힘을 발휘할 때 진가를 드러낸다.
자주 사용하는 df 속성들 정리
df.head() # 상위 5개 행 보기
df.columns # 컬럼명 확인
df.index # 인덱스 정보
df.dtypes # 데이터 타입
df.describe() # 기초 통계 요약
728x90
반응형
'python > Pandas | Numpy' 카테고리의 다른 글
| [Pandas] 데이터 타입 확인 및 변환 – dtypes, astype() (0) | 2025.04.24 |
|---|---|
| [Pandas] 결측치(NaN) 처리 (0) | 2025.04.24 |
| [Pandas] 정렬과 순위 매기기 – sort_values, rank (0) | 2025.04.24 |
| [Pandas] Boolean Indexing (조건 필터링) (0) | 2025.04.24 |
| [Pandas] 인덱싱 – loc vs iloc (0) | 2025.04.24 |