python/Pandas | Numpy
[Pandas] filter()
Balang
2025. 4. 24. 11:16
728x90
데이터 전처리나 EDA(탐색적 데이터 분석)를 하다 보면 다음과 같은 일이 자주 있다:
- 컬럼이 너무 많은데, 이름에 'score'가 들어간 것만 추출하고 싶다
- '2023'으로 시작하는 행(index)만 뽑고 싶다
- 복잡한 조건이 아니라 이름 기반으로만 간단히 필터링하고 싶다
이럴 때 Pandas의 filter() 함수는 가볍고 직관적인 선택 도구가 되어준다.
예제 데이터
import pandas as pd
df = pd.DataFrame({
'user_id': [1, 2, 3],
'score_math': [90, 80, 70],
'score_eng': [85, 75, 65],
'score_sci': [88, 78, 68],
'age': [25, 30, 35]
}, index=['2022_A', '2023_B', '2023_C'])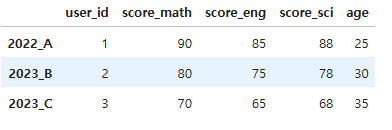
1. 예제: 특정 문자열이 들어간 열만 선택 (like)
df.filter(like='score', axis=1)
→ 'score'가 들어간 모든 열을 선택
2. 예제 정규표현식으로 열 선택 (regex)
df.filter(regex='.*_eng$', axis=1)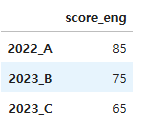
→ 'eng'으로 끝나는 컬럼만 선택 (영어 점수)
3. 예제 정확한 열 이름만 선택 (items)
df.filter(items=['user_id', 'age'], axis=1)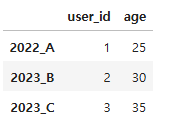
→ 특정 컬럼들만 추출하고 싶을 때 가장 명확한 방식
4. 예제 행 이름(index) 필터링
df.filter(like='2023', axis=0)
→ 인덱스에 '2023'이 포함된 행만 선택
5. 예제 정규표현식으로 행 필터링
df.filter(regex='.*_C$', axis=0)
→ 인덱스가 _C로 끝나는 행만 선택
주의사항
| 실수 유형 | 설명 |
| axis 지정 실수 | axis=0은 행, axis=1은 열. 잘못 지정하면 엉뚱한 결과 |
| like는 부분 포함 | "score"가 'score_math' 포함되는지 보는 것. 전체 일치 아님 |
| regex는 정규표현식 문법 숙지 필요 | .* , ^ , $ 등의 의미 정확히 알아야 함 |
팁
- filter(like='2023', axis=0) → 특정 연도 데이터만 추출
- filter(regex='^score_', axis=1) → 'score_'로 시작하는 모든 컬럼 선택
- filter(items=list(df.columns[:3]), axis=1) → 앞 3개 열만 선택
Pandas의 filter()는 조건 없이 이름 기반만으로 데이터 선택을 간단하게 처리할 수 있는 함수다.
정규표현식, 부분일치, 이름 리스트 등을 활용해 효율적인 전처리를 만들 수 있다.
728x90
반응형